안녕하세요,
저는 최근 10년치 ES 선물 데이터(ESH16부터 ESZ26까지)를 정리하는 작업을 마쳤습니다. 원래 CSV 파일로 저장된 데이터를 계속 처리하는 게 너무 번거롭고 느려서 결국 Apache Parquet 포맷으로 변환했어요.
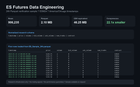
데이터 양이 무려 22억 건에 달하는데, CSV로는 다룰 수가 없었거든요. Parquet으로 옮기니 용량이 7.1GB로 22배나 줄었고, Python에서 Polars 라이브러리를 써서 읽는 속도도 훨씬 빨라졌습니다.
가장 힘들었던 부분은 롤오버 처리였어요. 분기별 선물 만기 시 중복 거래량 집계가 되지 않도록 엄격하게 기간 스케줄을 짜야 했는데, 이걸 제대로 안하면 거래량 데이터가 엉망이 됩니다. 그래서 타임스탬프, 가격, 거래량 등을 일관된 형식으로 정리했으며, 정가(close)를 대표 가격으로 사용했습니다.
지금은 Polars의 scan_parquet()를 써서 필요한 구간만 느긋하게 불러오고 있는데, 노트북에서 10년치 데이터를 몇 초 만에 조회할 수 있어서 정말 편리합니다.
데이터 인프라를 구축하거나 퀀트 작업을 준비하는 분들께 참고가 되길 바라며, 파켓 파일, 타임스탬프 작업, Polars 사용법에 대해서도 언제든 이야기 나눌 준비가 되어 있습니다.
첨부한 스크린샷은 24시간 샘플 데이터 압축 테스트 결과인데, 90만 건가량이 들어간 Parquet 파일은 2.1MB지만 동일 CSV 파일은 46MB가 넘습니다.
🧐 배경 설명 및 요약
이 글은 ES 선물 데이터를 10년 이상 엑셀이나 CSV가 아닌 더 효율적인 포맷으로 변환하는 과정을 공유하려는 내용입니다. 작성자는 CSV 파일이 너무 크고 느려서 분석에 큰 어려움을 겪었고, 이를 해결하기 위해 Apache Parquet이라는 저장 방식으로 전환했습니다. 특히 선물 만기 때 계약을 교체하는 롤오버 작업 논리가 까다로운데, 이를 꼼꼼히 설계하지 않으면 거래량 데이터가 중복 집계되어 잘못된 분석으로 이어집니다.
이 글의 핵심은 대용량 시계열 데이터를 효율적이고 정확하게 다루려는 사람들에게 도움이 되도록, 데이터 전처리와 저장 체계를 어떻게 개선했는지 전하는 데 있습니다. Polars 같은 최신 데이터 처리 도구와 Parquet 포맷을 활용하면 빠른 속도로 필요한 구간만 불러와 작업할 수 있어 개인투자자나 퀀트들에게 유용합니다.
마지막으로 댓글에서는 비슷한 경험을 한 다른 투자자가 자신도 Parquet와 Polars 조합으로 빠른 데이터 조회를 실현했다고 전하며, 데이터 구조 설계에 관해 궁금한 점이 있으면 소통하자고 제안합니다.
댓글 (0)
로그인하고 댓글을 작성하세요.
아직 댓글이 없습니다.